
Bio
I am a computer science graduate, completed my Masters' degree in computer science and IT from Tribhuvan University, Nepal.
My research interests are in Computer Vision, Natural Language Processing, Machine Learning and AI. I like eating, programming, travelling, sleeping and drinking coffee.
Education & Training
-
M.Sc. 2012
M.Sc. in Computer Science and IT
Tribhuvan University, Central Dept. of Computer Science & IT, Kirtipur, Kathmandu, Nepal
-
B.Sc. 2008
B.Sc. in Computer Science and IT
Tribhuvan University, Siddhanath Science Campus Mahendranagar, Kanchanpur, Nepal
-
P.C.L 2005
P.C.L. in Physical Science
Tribhuvan University, Siddhanath Science Campus Mahendranagar, Kanchanpur, Nepal
-
S.L.C. 2002
Hunainath Secondary School, Ratamata, Darchula Nepal
Honors, Awards and Grants
-
June 2014Employee of the Month AwardEmployee of the Month Award from TekTak Nepal Pvt. Ltd.
-
2013Most Creative Employee AwardMost Creative Employee Award from TekTak Nepal Pvt. Ltd.
-
2013UGC Faculty Research Grant AwardFaculty Research Grant Award from University Grants Commission
-
2011Research Grant for Master’s ThesisResearch Grant for Master’s Thesis from Nepal Academy of Science and Technology (NAST). Thesis title was
Off-line Nepali handwritten character recognition using Multilayer Perceptron (MLP) and Radial Basis Function (RBF) neural networks.
Research Summary
Recent trends in machine intelligence have resulted in new requirements for algorithms and experiments in almost all fields of the universe even galaxies and beyond. Much of my work centers on new formulations and experiments that helps human life to become much easier and happier.
Interests
- Time, Money and Happiness
- Image Processing and Computer Vision
- Natural Language Processing
- Data Mining and Pattern Recognition
- Machine Learning and Deep Learning
- Artificial Intelligence and Robotics
Research Projects
-

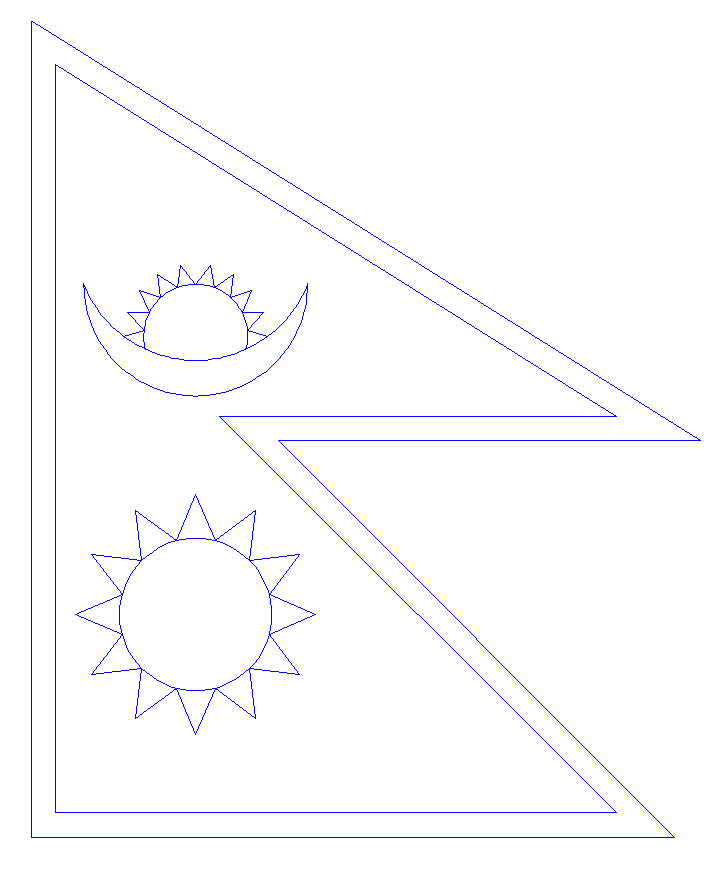
The national flag of Nepal is the most mathematical and world's only non-quadrilateral flag. It consists of two juxtaposed triangular architecture with a white emblem of the crescent moon having eight rays visible out of sixteen in the upper triangle and a white emblem of a twelve-rayed sun in the lower triangle. The flag is bordered with a deep blue color representing the peace and harmony, and rectangles are filled with crimson red (the color of rhododendron- Nepal's national flower) representing the victory and bravery. The two triangles symbolized the Himalayan Mountains; the moon represents the serenity of the Nepalese people and the shade and cool weather in the Himalayas, while the sun stands for the fierce tenacity of the Nepalese people, and, the heat and higher temperatures of the lower parts of Nepal. The moon and the sun are also said to express the hope that the nation will endure as long as these heavenly bodies. This modern architecture of the flag was come into existence after December 16, 1962. Before that, the sun and the crescent moon had human faces.

Research Publications
Image processing, Computer vision, Natural language processing, Machine learning, Deep learning, Pattern recognition, Artificial Intelligence, ...
Filter by type:
Deep Learning Based Large Scale Handwritten Devanagari Character Recognition
Abstract
In this paper, we introduce a new public image dataset for Devnagari script: Devnagari Character Dataset(DCD). Our dataset consists of 92 thousand images of 46 different classes of characters of Devnagari script segmented from handwritten documents. We also explore the challenges in recognition of Dev- nagari characters. Along with the dataset, we also propose a deep learning architecture for recognition of those characters. Deep Convolutional Neural Network have shown superior results to traditional shallow networks in many recognition tasks. Keeping distance with the regular approach of character recognition by Deep CNN, we focus the use of Dropout and dataset increment approach to improve test accuracy. By implementing these techniques in Deep CNN, we were able to increase test accuracy by nearly 1 percent. The proposed architecture scored highest test accuracy of 98.47% on our dataset.
Automatic Nepali Number Plate Recognition with Support Vector Machines
Abstract
Automatic number plate recognition is the task of extracting vehicle registration plates and labeling it for its underlying identity number. It uses optical character recognition on images to read symbols present on the number plates. Generally, numberplate recognition system includes plate local- ization, segmentation, character extraction and labeling. This research paper describes machine learning based automated Nepali number plate recognition model. Various image processing algorithms are implemented to detect number plate and to extract individual characters from it. Recognition system then uses Support Vector Machine (SVM) based learning and prediction on calculated Histograms of Oriented Gradients (HOG) features from each character. The system is evaluated on self-created Nepali number plate dataset. Evaluation accuracy of number plate character dataset is obtained as; 6.79% of average system error rate, 87.59% of average precision, 98.66% of average recall and 92.79% of average f-score. The accuracy of the complete number plate labeling experiment is obtained as 75.0%. Accuracy of the automatic number plate recognition is greatly influenced by the segmentation accuracy of the individual characters along with the size, resolution, pose, and illumination of the given image.
Sentiment Analysis on Nepali Movie Reviews using Machine Learning
Abstract
This research article presents machine learning methods for detecting the sentiment expressed by movie re- views. The semantic orientation of a review can be positive or negative. Analysis of opinion for particular product, news or document could be beneficial to many companies, institutions and individuals for marketing, advertising, question answering, product selection and so on. We have created a Nepali movie review dataset with total 500 samples having 250 samples per each positive and negative class of sentiment from various online sources. Sentiment analysis system implements various natural language processing techniques for document preprocessing and feature extraction. Naive Bayes based machine learning technique is used for the classification of the sentiment. Empirical results shows, classification accuracies are, 79.23% of precision, 78.57% of recall and 78.90% of F-score.
Off-line Nepali handwritten character recognition using Multilayer Perceptron and Radial Basis Function neural networks
Abstract
An off-line Nepali handwritten character recognition, based on the neural networks, is described in this paper. A good set of spatial features are extracted from character images. Accuracy and efficiency of Multilayer Perceptron (MLP) and Radial Basis Function (RBF) classifiers are analyzed. Recognition systems are tested with three datasets for Nepali handwritten numerals, vowels and consonants. The strength of this research is the efficient feature extraction and the comprehensive recognition techniques, due to which, the recognition accuracy of 94.44% is obtained for numeral dataset, 86.04% is obtained for vowel dataset and 80.25% is obtained for consonant dataset. In all cases, RBF based recognition system outperforms MLP based recognition system but RBF based recognition system takes little more time while training.
Off-line Nepali Handwritten Character Recognition Using MLP and RBF Neural Networks
Abstract
An off-line Nepali handwriting recognition, based on the neural networks, is described in this research work. For the recognition of off-line handwritings with high classification rate a good set of features as a descriptor of image is required. Two important categories of the features are described, geometric and statistical features for extracting information from character images. Directional features are extracted from geometry of skeletonized character image and statistical features are extracted from the pixel distribution of skeletonized character image. The research primarily concerned with the problem of isolated handwritten character recognition for Nepali language. Multilayer Perceptron (MLP) & Radial Basis Function (RBF) classifiers are used for classification. The principal contributions presented here are preprocessing, feature extraction and MLP & RBF classifiers. The another important contribution is the creation of benchmark dataset for off-line Nepali handwritings. There are three datasets for Nepali handwritten numerals, Nepali handwritten vowels and Nepali handwritten consonants respectively. Nepali handwritten numeral dataset contains total 288 samples for each 10 classes of Nepali numerals, Nepali handwritten vowel dataset contains 221 samples for each 12 classes of Nepali vowels and Nepali handwritten consonant dataset contains 205 samples for each 36 classes of Nepali consonants. The strength of this research is efficient feature extraction and the comprehensive classification schemes due to which, the recognition accuracy of 94.44% is obtained for Nepali handwritten numeral dataset, 86.04% is obtained for Nepali handwritten vowel dataset and 80.25% is obtained for Nepali handwritten consonant dataset.
Blog
Image processing, Computer vision, Natural language processing, Machine learning, Deep learning, Pattern recognition, Artificial Intelligence, ...




Contact & Meet Me
I would be happy to talk to you if you need my assistance in your research or whether you need any research discussion about any subjects of my field.
I am happy to join any coffee `guffs` on my leisure time.
- Office: ---------
- ashokpant87@gmail.com
- ashokpant87
- #ashokpant_
- np.linkedin.com/in/asocapant
© www.ashokpant.com.np, 2016. Powered by Faculty - Responsive Academic Personal Profile